
Fast, reliable new molecular dynamic simulation methods set to speed up research are under investigation by GSK
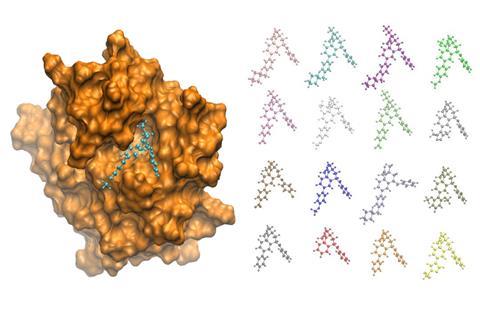
UK scientists have devised two molecular dynamics simulation methods that they say could enable genetically-targeted drug development.1 Pharma giant GlaxoSmithKline (GSK) has already used them to simulate compounds interacting with a protein section known as a bromodomain, linked to cancer and inflammatory disease. GSK concluded ‘that the approach warrants further investigation as it has the potential to greatly reduce discovery and development times’, says Peter Coveney from University College London (UCL).
The pharmaceutical industry regularly uses molecular dynamics simulations of interactions between proteins and drug candidates. However, the UCL team has recently shown that a fundamental randomness makes single simulations unreproducible. ‘Yet most publications have reported the behaviour of a single simulation,’ Coveney says.
Coveney is involved in the €210 million (£180 million) European Virtual Physiological Human initiative supporting personalised medicine. ‘Key to all of this is to ensure one can produce rapid, accurate, precise and reproducible predictions,’ he says. That could help rank drugs against the precise protein structures each person’s genes encode.
Consequently his team devised a new molecular dynamics approach to calculate binding affinities – the energy released when compounds slot into proteins – based on the thermodynamic integration (TI) method. Because it’s very difficult to work out absolute binding affinities, TI considers differences between binding affinities of two small organic compounds bound to a protein. The new approach simulates a gradual transformation from one compound to the other, taking several simulated snapshots after each of several small steps in this ‘alchemical’ transition.2
Calculations, including averages across each intermediate point in the transformation, give the relative binding affinity for a pair of compounds, Coveney explains. That approach is more reliable and less subject to randomness than previous methods using a single transformation step. The calculations are also fast because the algorithm is designed so that they can be run in parallel, independently, suiting modern supercomputers.
The team’s second method calculates absolute binding affinities, also using large-scale averaging. As this is a greater challenge the approach is less accurate, but can avoid structural limitations faced when transforming between similar compounds in TI.
Colin Sambrook Smith, director of computational sciences and informatics at Sygnature Discovery in Nottingham, UK, calls the bromodomain results ‘encouraging’. ‘The authors mention expanding this work to other proteins and this will be awaited with much interest,’ he says. He adds that a key early challenge will be building software to handle the large datasets the approach generates.
References
1 S Wan et al, J. Chem. Theory Comput., 2016, DOI: 10.1021/acs.jctc.6b00794
2 A P Bhati et al, J. Chem. Theory Comput., 2017, 13, 210 (DOI: 10.1021/acs.jctc.6b00979)















No comments yet