More than 90% of the potential individual amino acid mutations possible introduced into cancer-linked protein
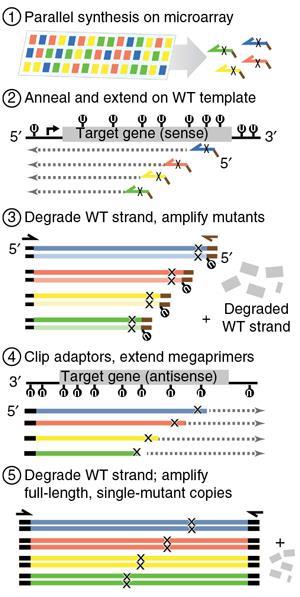
Researchers in the US have developed a faster and less costly way to investigate the effects of genetic mutations on proteins, which should offer new insights into hereditary diseases. The technique uses DNA microarrays to help synthesise thousands of different versions of a gene – each with a single amino acid mutation in the resulting protein. They used their method to build DNA libraries of mutant proteins, including tumour suppressor p53 – a protein linked to cancer in humans.
‘We expect that the p53 library could be a useful reagent for studying how variants in p53 contribute to tumourigenesis,’ says Jacob Kitzman from the University of Michigan, whose group developed the method – called programmed allelic series (PALS) – together with Jay Shendure and colleagues at the University of Washington.
The p53 protein is made up of 393 amino acid residues, each of which is coded for by a triplet of DNA bases (a codon) on the gene, so there are thousands of potential mutations which might affect its structure. ‘PALS uses collections of hundreds or thousands of oligonucleotide primers, each containing a fragment of a target gene, but designed with a different mutation such as a codon substitution,’ says Kitzman. The primers themselves are synthesised in parallel on the surface of a DNA microarray, which makes the process much faster and more cost effective than previous approaches that target only a few sites at a time. To make multiple copies for the library the primers are released into solution along with the wild-type gene, and polymerase to replicate the DNA. ‘The end result is a library in which each copy carries one of the programmed mutations but otherwise matches the wild-type sequence,’ says Kitzman.
The team created two libraries in this way: one for p53 where 93.5% of the potential mutations were represented – 7345 out of 7860 possible amino acid substitutions, and one for the shorter yeast transcription factor Gal4 that covered 99.9% of mutations. They are making these freely available to the community via Addgene, an online database. ‘The global view this large dataset provides can be mined for new insights into a protein’s functional properties,’ says Kitzman. He adds that the team are also planning to apply the approach to other disease-related proteins.
‘This method seems to have a niche in the rapid generation of libraries of short protein stretches for large-scale knockout screens,’ says Tim Whitehead from Michigan State University, who uses similar methods for protein engineering studies. He says that the use of microarrays for generating primers ‘significantly decreases reagent costs for library preparation’, but adds that improvements would be needed to deal with longer DNA sequences.











No comments yet