
‘Synthetic data’ is being used in chemistry, but is it something we should worry about? Hayley Bennett explains
For scientists, faking or making up data has obvious connotations and, thanks to some high-profile cases of scientific misconduct, they’re generally not positive ones. Chemists may, for example, be aware of a 2022 case in which a respected journal retracted two papers by a Japanese chemistry group that were found to contain ‘manipulated or fabricated’ data. Or the case of Bengü Sezen, the Columbia University chemist who, during the 2000s, ‘falsified, fabricated and plagiarised’ data to get her work on chemical bonding published – including fixing her NMR spectra with correcting fluid.
‘Synthetic data’, unlike dishonestly made-up data, is created in a systematic way for legitimate reasons, however, usually by a machine – and for a variety of reasons. Synthetic data is familiar to machine learning experts, and increasingly to computational chemists, but relatively unknown to the wider chemistry community, as Keith Butler, a materials researcher who works with machine learning methods at University College London in the UK, acknowledges.
‘I don’t think very many people at all, in chemistry, would refer to synthetic data,’ he says, adding that it’s probably a confusing term for chemists not just because of the apparent associations with scientific misconduct, but because ‘synthetic’ in chemistry has another important meaning, relating to the way chemical compounds are made. But why are chemists making up their data, how is it any different to the simulations they’ve been making for decades and what are the implications?
Fake it to make it
In areas like health and finance, synthetic data is often used to replace real data from real people due to privacy concerns, or to deal with issues of imbalance, such as when people from certain ethnic groups aren’t well-represented. While researchers might like to use people’s personal medical records, for example, to inform their understanding of a new disease, that data is difficult to access in the quantities or levels of detail that would be most useful. Here, the creation of synthetic data, which mirrors the statistical features of the real-world data, offers a solution. ‘You’re not taking a whole dataset and just masking it,’ explains Benjamin Jacobsen, a sociologist at the University of York in the UK, whose work focuses partly on the use of synthetic data. ‘The promise of synthetic data is that you can train a model to understand the overall distribution of the particular dataset.’ In this way, synthetic data draws from real-world sources, but can’t be traced back to real individuals. In the chemical sciences, though, synthetic data relates more to the behaviour of molecules than people and so as Butler notes, it’s used for ‘a very different reason’.
Synthetic data is generated by algorithms and for algorithms
In some ways, legitimately ‘made-up’ data is nothing very new in chemistry. Areas such as materials and drug discovery, for example, have long used what’s referred to as ‘simulated’ or ‘calculated’ data to expand the chemical space for exploration – the data might describe predicted properties of new materials or potential drug compounds. What’s different now is that made-up data, whether it’s considered synthetic, simulated or calculated, is being used in combination with machine learning models. These AI models are algorithms capable of making sense of vast quantities of data, which could be from real experiments or made up (or a combination of both). They learn patterns in the data and use them to make classifications and predictions to provide valuable insights to humans – whether or not it’s clear how the machines have delivered them.
Synthetic data is not just an input for AI models – it’s an output from them too. Jacobsen, in fact, previously defined synthetic data as data ‘generated by algorithms and for algorithms’, although chemists may not be concerned with having such a strict definition. Some of the techniques commonly used to create it are related to those used in making deepfakes. In the same way that deepfakers might ask their machines to generate realistic-looking faces and speech, chemists might prompt theirs to generate realistic-looking chemical structures.
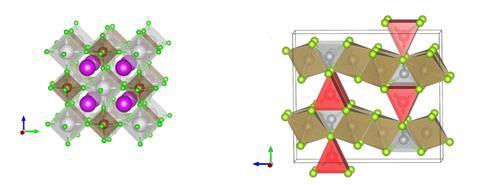
Another option for generating synthetic data is large language modelling – the basis of generative AI tools like ChatGPT. This is an approach Butler’s team recently used to build an app that can produce a hypothetical crystal structure for a compound based on a chemical formula, which is typed in as a ‘prompt’ (like a question in a chat). More advanced versions of such tools, which would ‘know’ more of the rules of chemistry, could prove invaluable in the search for new materials. ‘If you could prompt [it] by saying “produce me a plausible chemical structure that absorbs light well and is made only from Earth-abundant elements”, that’s actually interesting,’ says Butler. ‘The problem being that you want to make sure that it’s reasonable and viable so that you don’t start telling people things that are impossible to make.’
Teaching the machines
Applications for synthetic data in the chemical sciences abound. However, for those who are less well-acquainted with machine learning, it can be hard to get a grip on what synthetic data is and how it can be so useful to chemists when it’s not actually real. Here, an example may help.

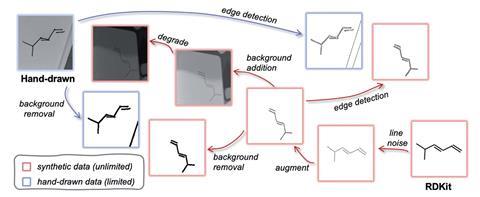
Most students of chemistry learn, fairly early on, to sketch out a chemical structure by hand, but transferring that structure from a piece of paper to a computer could be a tedious task. It would be useful if there was a quick way of doing it – say, by taking a picture of the sketch on your phone. At Stanford University in California, US, Todd Martinez and his team set about tackling this problem, their idea being to teach a machine learning model how to recognise hand-drawn chemical structures so that they could be quickly converted into virtual versions. However, to do this using real data, they would have needed to train their data-hungry model with a vast dataset of hand-drawn structures. As Martinez notes, even someone who can draw really fast is only going to be able to churn out a handful a minute. ‘We did try,’ he recalls. ‘We got 30 people together and spent hours just doing this, but we were only able to get 1000 structures or something. You need this data in the hundreds of thousands.’
So, instead, they developed a process for ‘roughing-up’ half a million clean, artificially generated chemical structures made with well-known software called RDKit and sticking them onto backgrounds to simulate photographs of hand-drawn structures. Having ingested this synthetic data, combined with a much smaller sample of real hand-drawn structures, their machine learning approach was able to correctly identify hand-drawn hydrocarbon structures 70% of the time – compared to never when trained just with their limited hand-drawn data (and only 56% of the time with the clean RDKit structures). More recently, they developed an app that turns hand-drawn structures directly into 3D visualisations of molecules on a mobile device.
Had it been fed half a million genuine, hand-drawn structures, Martinez’s model might have performed even better, but the real data just wasn’t available. So in this case, using synthetic data was a solution to the problem of data sparsity – a problem described as one of the main barriers to the adoption of AI in the chemical sciences. As Martinez puts it, ‘There are lots of problems in chemistry – actually, most problems, I would say – where there is insufficient data to really apply machine learning methods the way that practitioners would like to.’ The cost savings to be made by using synthetic data, he adds, could be much larger than in his molecular recognition example, because elsewhere this made-up data wouldn’t just be replacing data that it takes someone a few seconds to draw, but data from expensive, real-life experiments.
Experimental excess
There’s certainly no shortage of such experimental data at the Rutherford Appleton Laboratory in Oxfordshire. Here, ‘petabytes and petabytes’ of data are produced, Butler says, by real-life experiments in which materials are bombarded with subatomic particles in order to probe their structure. But Butler’s collaborators at the facility face a different problem: a massive surplus of ‘unlabelled’ data – data that is effectively meaningless to many machine learning models. To understand why, think back to the previous example, where each hand-drawn chemical structure would need a label attached to teach the machine learning model how to recognise it. Without labels, it’s harder for the AI to learn anything. ‘The problem is that it’s really expensive to label that kind of experimental data,’ Butler says. Synthetic data, though, can be generated ready-labelled and then used as training data to help machine learning models learn to interpret the masses of real data produced by the laboratory’s neutron-scattering experiments – a line of thinking Butler and co-workers explored in a 2021 study.
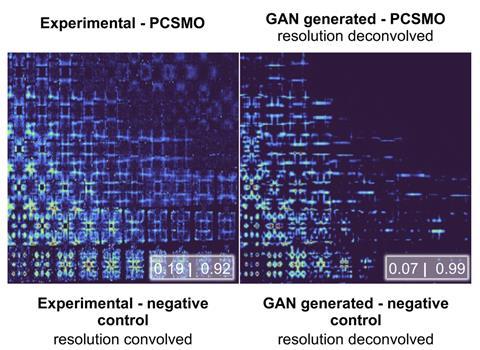
In the study, they trained their models with thousands of synthetic spectra – images in the same format as those they got from real neutron scattering experiments, but that were created via theoretical calculations. What they realised, though, was that when it came to interpreting real spectra, the models trained on simulated data just weren’t very good, because they weren’t used to all the imperfections that exist in real-world experimental spectra. Like the fake, hand-drawn chemical structures made by Martinez’s team, they needed roughing up. As a solution, Butler’s team came up with a way to add experimental artefacts including noise to the clean synthetic data. He describes it as akin to a filter you might apply to selfie, except instead of giving a photo of your face the style of a Van Gogh painting, it gives a perfect, simulated spectrum the style of a messier one from a real experiment. This restyling of synthetic data could be useful more broadly than in neutron scattering experiments, according to Butler.
Another area in which synthetic data could have an important impact is in combination with AI approaches in drug discovery. Though, as in other fields, the terminology could be a little off-putting. ‘People are a bit shy to accept synthetic data [perhaps because] it sounds like it’s lower quality than real data,’ says Ulrich Zachariae, a drugs researcher at the University of Dundee in the UK. Zachariae’s recent work has focused on searching for new compounds to target antibiotic-resistant Gram-negative bacteria like Pseudomonas aeruginosa, which causes life-threatening infections in hospital. One of the issues slowing down the search is that these bugs’ outer shells are virtually impenetrable, and while machine learning models could help make useful predictions about which compounds might work, there’s a lack of data on bacterial permeability to feed the models.
That dataset provided us with enough ‘input data’ that we could understand what was going on
To start tackling the permeability problem, Zachariae’s team first constructed a model with what data they had – data that came from existing antibiotics – and used it predict whether other compounds would be good ‘permeators’, or not. This worked well, but didn’t explain anything about why one compound was better than another. The researchers then wanted to probe the effects of small differences in chemical structure on permeability , but this required lots more data. So, to generate more, they used their own machine learning model to predict the properties of hundreds of thousands of (real) compounds for which there was no experimental data on permeability – creating a huge new synthetic dataset. ‘That dataset provided us with enough “input data” for [the additional analysis] that we could understand what was going on and why these compounds were good permeators or not,’ Zachariae explains. They were then able to suggest chemical features, including amine, thiophene and halide groups, that medicinal chemists should look out for in their hunt for new Gram-negative antibiotics.
For Martinez, understanding why machine learning models make the predictions they do is another key motivation for using synthetic data. The internal workings of AI models can be difficult to unravel – they’re widely referred to as black boxes – but Martinez says he thinks of synthetic data as a ‘tool’ to sharpen a particular model that is producing that data, or to understand its essence in a simpler form. ‘I think you can see examples of people groping towards this, but I don’t know that it’s clearly stated,’ he muses. Martinez’s interests lie mainly in quantum chemistry, where more traditional computational models are used to solve theoretical problems. Addressing the same problems with machine learning may be a way to get to solutions faster while also – with the help of synthetic data – getting to the heart of what the AI models have learned. In this way, chemists may be able to improve their more traditional models.
Reality check
But what are the risks of using data that isn’t real? It’s hard to answer this question at this point. In other fields, the risks often relate to people whose data was absorbed to generate synthetic data, or who are affected by the decisions it is used to make. As Jacobsen notes, the risks are going to vary depending on the application area. ‘Chemists have to delineate exactly “How do we frame what risk is in this context?”’ he says.
In the drug discovery space, Zachariae wonders if there is any more risk associated with artificially generated data than with simulated data used in the past. ‘From a purely scientific perspective, I don’t see how it’s any different from previous cycles of predictions, where we just used physical models,’ he says, adding that any ‘hit’ molecule identified using AI and synthetic data would still have to go through rigorous safety testing.
The risk is that we lose credibility if our predictions don’t match up with reality
Martinez, though, sees a potential problem in areas of theoretical chemistry where there is no ‘real’ or experimental data on which to train machine learning models – because that data can only be arrived at by computational means. Here, synthetic data may effectively be the norm, although ‘the magic words’ often aren’t mentioned, he says, because chemists aren’t familiar with them. In quantum chemistry, for example, a molecule’s geometry can be used to compute its energy – and now machine learning models are trained, based on existing theory, to take in geometries and spit out energies, just in faster and cheaper ways. However, since traditional methods are more accurate for smaller molecules than bigger ones and there’s no way of experimentally checking the results, machine learning algorithms trained to spit out energies for big molecules could be doing a poor job – which could be a concern if millions of data points are being generated. ‘The interesting point about synthetic data in this context is that these issues do not seem to always be at the forefront of the community’s thinking,’ Martinez says. ‘This seems to be because the synthetic nature of the data implies tight control over the training dataset and this can give a false confidence in data correctness and coverage.’
In materials discovery, similar concerns surround the use of machine learning to predict stable chemical structures – as Google DeepMind researchers have done – in chemical spaces where the existing theory was not necessarily that accurate. The risk, says Butler, ‘is that we lose credibility’ (and funding) if the properties of predicted materials don’t match up with reality. So, while ‘making up’ data may mean something different these days, it’s worth remembering that there could still be a lot at stake if it’s not done well.
Hayley Bennett is a science writer based in Bristol, UK














No comments yet