Is chemistry an information science after all?
When a concept starts cropping up in science everywhere you look, you have to suspect that it is either very profound or very trivial. As far as information theory is concerned, I’m still putting my money on the former.
No sooner had Claude Shannon introduced information theory to communications technology in the 1940s than it popped up in molecular biology, at the heart of the digital code of DNA. Soon after, while computer science seized on ideas by the likes of John von Neumann and Alan Turing to manipulate strings of bits, physicist John Wheeler began to think of physical law in informational terms. Thanks to his work and that of others, quantum mechanics and thermodynamics are among the areas of physics being formulated as information theories.
What of chemistry? At face value, it seems bound by principles less reducible to bits: the laws of chemical combination have a more complex foundation, dictated partly by the analogue calculus of energetics and partly by the complicated combinatorics of valence states. Yet the idea of making chemistry an information science has been around for decades.
Building to code
In the 1990s, Nobel laureate Jean-Marie Lehn argued that the principles of spontaneous self-assembly and self-organisation, which he had helped to elucidate in supramolecular chemistry, could give rise to a science of ‘informed matter’ beyond the molecule.1
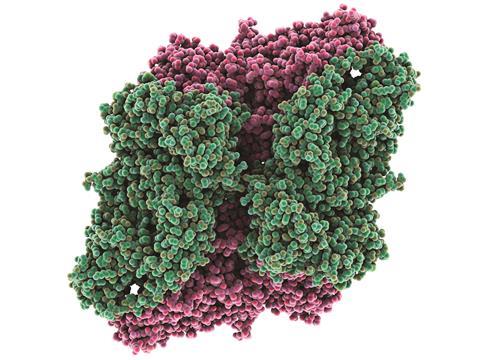
In short, Lehn’s idea amounted to rewriting rules of chemical combination with those of your own choosing, so that molecules are programmed to assemble themselves in whatever manner you please. That might sound optimistic, but it’s turning out that the information paradigm embodied in DNA is ideal for creating Lehn’s informed matter. Rather ironically, it seems likely that this notion of DNA – as a molecule that can be programmed to produce a specific output structure – may work better for chemistry than it does for biology, where the rules of information processing that take us from genotype to phenotype are still opaque and quite possibly not self-contained at all.
Strands of DNA can be programmed to zip together via their sequences. Chemists have known for decades how to exploit this specificity to make topologically complex molecules, or to assemble nanostructures from components tagged with DNA complementary to that at the intended docking sites. By controlling the valency and the stiffness of the DNA linkages, one can make well-defined nanoscale architectures built from programmable components using a kind of ‘directional glue’.
One way to make use of this programmability is for DNA-templated synthesis of molecules, where the tags bring the reactants into forced proximity – an idea being developed by David Liu at Harvard University. Lehn, however, always had his sights set beyond the molecule: on the kind of multiscale assemblages that do the work of living cells, such as the proteins and pigments of the photosynthetic apparatus or the protein/nucleic acid machinery of the ribosome. Assembly here is generally dictated by subtle forces that have been fine-tuned by evolution – such as water-mediated interactions of protein surfaces – which are still imperfectly understood. DNA linkers are easier to understand, and in principle more versatile, universal and switchable. What’s more, biotechnology is producing an ever-expanding toolkit for cutting and editing such linkages.
Controlling the design
Chad Mirkin, of Northwestern University, US, was involved in the early work on DNA-based nanoparticle assembly and has been refining and expanding DNA-templated assembly ever since. His latest example of the art, developed with Janet McMillan, shows yet again how this approach gives the chemist new scope for control and design of supramolecular architectures. McMillan and Mirkin have given proteins DNA tags that allow them to be assembled into one-dimensional arrays – protein wires, you might say, in which the individual molecules are not only linked but orientated relative to one another.2
They used a ‘workhorse’ protein: the enzyme β-galactosidase, which hydrolyses those eponymous sugars. The DNA linker is attached to cysteine residues in the protein via a coupling reaction between the cysteine’s thiol group and a maleimide substituent attached to the 10-base-pair tag. The tags are only wanted at certain points on the protein surface, however, so all the other cysteines ‘visible’ to the solvent have to be replaced by serine. The planned result is a protein, about 12nm by 17nm, with two tags on the top and bottom faces that will pair up with complementary ones on other β-galactosidase molecules above and below.
It’s not hard to imagine places to go next. You could make alternating ‘sandwich’ stacks of two or more different proteins. You could investigate electron- or energy-transfer processes down the ‘wires’, perhaps varying the separation of successive units according to the length of the DNA linkers. You could even extend the assembly in other directions – Mirkin and colleagues have already made 3D crystals from DNA-linked objects.3 The technique could be used to produce ‘synthetic crystals’ of proteins that are hard to crystallise, making them easier to study structurally. Mirkin acknowledges this as a goal, though it’s still a challenge to ensure good rotational ordering of the units too.
He also imagines assembling a sequence of enzymes that can conduct controlled chemical transformations, like robots on an assembly line, each with a specialised task.4 What’s more, there are ways of getting such assemblies into cells, which Mirkin says ‘opens up the ability use enzymes to make measurements inside cells and to create new classes of therapies’.
There’s evidently a lot you can do when you’re sufficiently well informed.
References
1. J–M. Lehn, Supramolecular Chemistry, VCH: Weinheim, 1995
2. J R McMillan & C A Mirkin, J. Am. Chem. Soc., 2018 DOI:10.1021/jacs.8b03403
3. J D Brodin, E Auyeung & C A Mirkin, Proc. Natl. Acad. Sci USA, 2015, 112, 4564 (DOI: 10.1073/pnas.1503533112)
4. J D Brodin et al, J. Am. Chem. Soc., 2015, 137, 14838 (DOI: 10.1021/jacs.5b09711)










1 Reader's comment