Network analysis provides insight into navigating chemical space
Two UK researchers have discovered that the network of reactions comprising organic chemistry shares statistical phenomena with social networks, and that the structure of this network is itself full of untapped chemical information.
Alexei Lapkin at the University of Cambridge began with the question of how to connect sustainably-sourced molecules with possible high-value chemical products. ‘Academics would always ask industrialists which high-value molecules they want, whereas industrialists would always come back with the answer “which molecules can you give us?”’
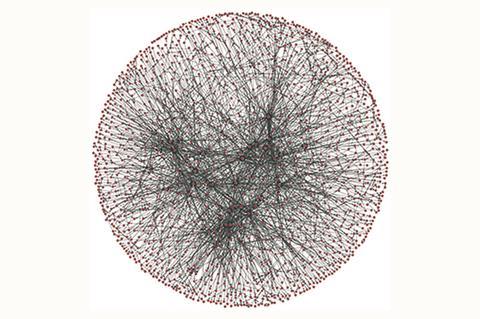
In order to develop a supply chain for transforming bio-based chemical feedstocks into useful molecules, Lapkin wanted to be able to look at the entire landscape of relevant reactions. His group member Philipp-Maximilian Jacob had the idea to statistically test a large data set of chemical reactions. So, using nearly 13 million reactions from the Reaxys database that originate from limonene, a bio-feedstock molecule, Lapkin and Jacob applied graph theory analysis to investigate and describe the connectivity of a section of what has previously been termed the Network of organic chemistry (NOC).
‘We have this large body of chemical data which exists out there in chemical databases being used passively,’ explains Jacob. Their objective was to get a better understanding of how that chemical space is organised and how to apply statistical methods to the data. Unlike previous work, they sought to examine the network without preconceptions about it being chemical data. Would it be possible to infer known chemical phenomena purely from statistical analysis of the network?
Networking opportunity
They converted the Reaxys data into a network using Python, with vertices representing molecules and edges representing the reactions between them. Using graph-tool and the powerlaw package, Lapkin and Jacob assessed key statistical properties of the network, such as the average number of reactions connecting each molecule, whether well-connected molecules tend to cluster together and the average number of reactions separating each pair of molecules.
Lapkin says their results show it is possible to apply certain statistical metrics to the NOC data and use it to predict reaction pathways. Anyone with access to the data can reproduce the duo’s findings using the same tools, and the results can be validated against the history of the network’s evolution.
Yury Suleymanov, whose work at The Cyprus Institute involves computational discovery of unexpected chemical reactions, highlights how new information causes the NOC to expand following a precisely defined evolution pattern. ‘The analysis of key network metrics indicated that it is possible to estimate the changes in the total number of chemical reactions for a given species when new, previously unknown and unexpected reactions are discovered in future.’
Judit Zador, an expert in reaction pathway search methods at Sandia National Laboratories, US, notes that the distribution of nodes with very large numbers of neighbours, such as the bio-based platform chemicals inspiring this work, is important to the global geometry of the network and to the structure of synthetic pathways. She stresses the potential broad interest in this work: ‘Researchers seeking to design new pathways may wish to reflect on these ideas, which may find application in other areas of chemistry, such as the reaction networks describing combustion or atmospheric chemistry.’
Suleymanov notes that the NOC also exhibits the ‘six degrees of separation’ observed in social networks. This means that it is, on average, ‘possible to produce any chemical species out of any other species within six or less steps of organic synthesis’ just as social network research has shown that you are, on average, no more than six social links away from any other living human. This finding could reveal shorter synthetic routes that may have been overlooked.
Looking to the future, Lapkin predicts that chemistry will depend progressively more on the algorithmic use of information, which is only possible if published research contains machine-readable data. ‘We would urge people to look into how easy it is to extract numbers out of publications if they want the papers to have long-term impact in the future of chemistry.’
References
P-M Jacob and A Lapkin, React. Chem. Eng., 2018, 3, 102 (DOI: 10.1039/c7re00129k)







No comments yet