

Artificial intelligence tools are transforming catalyst research, with new AI agents capable of completing in minutes what once took computational chemists days. Andy Extance explores how all scientists can benefit, from small groups to those at tech giants like Meta, Google and Nvidia
- AI is transforming catalyst research workflows, automating tasks once handled by computational chemists and enabling experimentalists to generate and test hypotheses more easily, with tools like ‘El Agente’ acting as integrated AI assistants.
- The technology promises to dramatically accelerate catalyst discovery and deployment, potentially shortening timelines that currently span 10–25 years by improving simulations, guiding experiments and supporting autonomous lab systems.
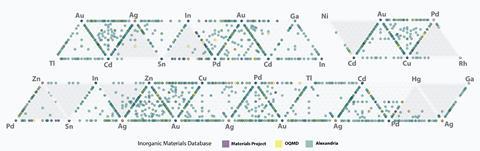
- Progress depends heavily on high-quality, standardised datasets, with major initiatives (eg Open Catalyst, Nomad, OQMD) working to expand computational and experimental data, though challenges remain around cost, consistency and limited data sharing in industry.
- Key challenges include experimental validation, scaling up processes, and data gaps, but advances in automation, machine learning models and AI-driven data extraction from literature are helping bridge these barriers and improve real-world industrial applications.
This was summary was generated by AI and checked by a human editor
When Varinia Bernales worked as a computational chemist in catalyst development at Dow Chemical in Michigan, US, ‘the day didn’t have enough hours’. ‘I spent a lot of time creating files, submitting calculations, troubleshooting,’ she says. ‘There were more experimentalists than computational people. Those experimentalists have a lot of ideas to test, and unfortunately, I didn’t have time to tackle them all.’ She would often take on validating hypotheses as a side project, to run on Friday afternoons or at weekends.
Before she moved to the University of Toronto in Canada in 2023, Bernales ‘wasn’t very fond of the hype on AI’, she tells Chemistry World. But now she says an AI agent that her team is working on, El Agente, which brings together different tools, can ‘fully replace … all the work I did at Dow Chemical’. The El Agente team collaborates closely with Nvidia, whose graphics processing units (GPU) chips power the AI revolution.

Understanding the molecular conformations involved in catalysis and building hypotheses to test experimentally has been ‘the privilege of the computational chemist’, Bernales says. Now, AI can play many roles in catalyst research, including fundamental molecular simulations and reviewing existing literature. Chemists experienced in catalysis can use El Agente to refine their hypotheses without knowing how to code. ‘With this tool, experimentalists will have another superpower,’ Bernales says. ‘We need it because we need to make progress faster and make quality of life better.’
It can take anywhere from a decade to 25 years to go from discovering a catalyst to using it in large scale applications, notes Ted Sargent from Northwestern University in Illinois, US. He believes that AI can speed up everything from discovery to assessing how catalyst performance varies over time in industrial use. ‘It’s the whole life cycle that we want to accelerate,’ Sargent says.
Chemists like Sargent are exploring how great that acceleration might be. His team has already exploited AI in catalyst discovery and now want to develop the resulting catalysts to enable ‘greater industrial impact’, he says. And several groups are seeking to go further than simply empowering chemists. They want to develop truly autonomous labs, where the AI agent is developing and testing hypotheses, integrating catalyst synthesis and characterisation, he explains. To enable that, they need larger, better datasets to train agents with.
To deliver these big dreams, AI is moving beyond its best-established role simulating catalyst systems. Researchers are increasingly testing results in the lab but are limited by the cost of simulations – even though AI is cheaper than traditional methods – and experiments. They can then combine new experimental measurements with existing data to refine AI systems. However, the amount of data currently available is limited, without standards for how it’s recorded, which makes it difficult to use for training. Solving commercially and societally useful problems with the catalysts will be the ultimate test. Researchers, including those at tech giants like Meta, Google and Nvidia, are confident AI is well-suited to that task.
Speeding up simulations with machine learning
Catalysis chemistry research is fundamentally complex, explains Graham Hutchings from the University of Cardiff, UK. ‘In any catalysis problem, there are lots of variables, and it’s a case of seeing how you’re varying them,’ he says. Historically, density functional theory (DFT) would support experimental hypothesis validation, he says, but AI is inverting that. ‘We’re turning it the other way round, with the theory driving.’
Hutchings heads up the Max-Planck-Cardiff Centre on the Fundamentals of Heterogeneous Catalysis (Funcat), joining with three Max Planck Institutes on catalyst research involving AI. The researchers are testing their approach on catalysts converting carbon dioxide into useful substances. They use a modelling approach from the Novel Materials Discovery (Nomad) project, where AI finds correlations between key physicochemical properties. An early study on the approach in 2021 involved thorough analysis of nine vanadium catalysts. ‘It needs very clean data,’ Hutchings says.
We can do a calculation in 25 seconds that is perfect
Trying to improve a catalyst is ‘tricky’, says Fernanda Duarte of the University of Oxford, UK, because modifying one atom can eliminate its effectiveness. ‘It works perfectly, or nothing. In catalysts, aggregates form at higher concentration that we cannot predict when we compute single molecules. All these small details really matter.’
Machine learning interatomic potentials (MLIPs) have been developed since 2010, replacing computationally demanding DFT molecular simulations. They enable simulations that consider complex mixtures, for example exploring interactions between catalysts and solvent environments, which weren’t previously possible, says Duarte. ‘Now, we can do a calculation in 25 seconds that is perfect.’
This makes simulation much cheaper than with DFT, but researchers still need to consider costs. Neural networks running the mathematical calculations that enable machine learning, which powers modern AI, run on GPUs. With AI growing so rapidly, GPUs are in short supply, and expensive; a GPU-powered computer that Duarte bought three years ago is more expensive today, she says. Researchers can use GPUs in data centres remotely, but this is still very expensive, she says. ‘Getting a machine that we can control is much more convenient,’ Duarte says.
The name MLIP arises because these machines learn from data they are trained with to create the AI models. Another way to keep costs down is to train them with smaller data sets, Duarte says. She notes that general chemistry models are often very good, but that their accuracy can be limited when looking at reactions in close detail. Her team has shown that they can create models dedicated to specific reactions with a few hundred DFT-simulated data points that are ‘highly accurate’ for specific chemistry.
The best dataset for AI modelling in chemistry so far is the Protein Data Bank (PDB). Containing over 250,000 physical protein crystal structures, it enabled protein folding prediction tool AlphaFold. Jahed Abed, a materials scientist at Google X in San Francisco, US, notes the power of pairing the database with the Critical Assessment of Protein Structure Prediction competition that led to AlphaFold. He says bringing such an open database and consistent competition with standardised evaluation metrics to catalysis could be a ‘tide that lifts all boats’. Abed formerly worked in the Fundamental AI Research (Fair) chemistry team at tech giant Meta, which is helping provide such open-source datasets. They ‘lower the barrier to entry, allowing external researchers to train their own models’, Abed says.
Building comprehensive catalyst datasets
The Open Catalyst project is a collaboration between Fair and Carnegie Mellon University in Pittsburgh, US. They aim to use AI to model and discover new catalysts for environmentally beneficial applications. To enable scientists everywhere to join in, Abed and colleagues released the Open Catalyst Experiments 2024 containing results from over 260 million DFT calculations for training machine learning models.
So far, Abed considers the Open Catalyst dataset as a foundation designed to be integrated with other datasets, ‘to accelerate discovery across the field’. To be impactful, datasets must be vast, diverse and reproducible. ‘The primary challenge in the experimental space is consistency,’ says Abed. There isn’t a standardised, reproducible way to generate data, which makes translating results to other groups ‘a significant hurdle’, he adds.
Meta incorporates the Open Quantum Materials Database (OQMD), created by Chris Wolverton and his group at Northwestern University in 2013, which contains DFT calculations for 1.4 million materials. The Nomad database of primarily computational data powering Hutchings’ work in Cardiff integrates OQMD to reach 2.7 million materials. Such broad training data helps AI tools learn ‘all of material science and synthesisability and structure’, explains Sargent. This minimises the amount of focused data needed to model a specific hypothesis about catalyst systems, he adds.
Around 2020, the Fair team had wanted to use its computing power to scale up a study from Sargent’s team, in which Abed was a PhD student at the time. The original study used machine learning to identify copper–aluminium electrocatalysts with record efficiency in converting carbon dioxide to ethylene. Abed then joined Meta full time in 2023, when he convinced his colleagues that including experimental data in OpenCatalyst was important. He enabled this by spearheading Fair in creating tools capable of running large-scale experimental campaigns.
The result was the Open Catalyst experiments 2024. Working with the University of Toronto and Dutch nanoparticle maker VSParticle, they made 572 samples in thousands of experiments and characterised them with x-ray fluorescence and x-ray diffraction characterisation. They prepared 441 gas diffusion electrodes and used them for carbon dioxide reduction and hydrogen evolution from water. They then used the data to train further models and made predictions using full-scale industrial setups to ensure smoother scale up and real-world relevance. Open Catalyst 2025 is due to be published soon, with Abed promising more discoveries.
Few other catalyst datasets incorporate much experimental data, Abed says, partly because doing so is ‘super expensive’. ‘Scaling physical experiments alongside extensive characterisation is notoriously cost-prohibitive,’ he says. This means it’s important to do the minimum characterisation needed to get ‘the exact right level of data richness required to train models effectively’, Abed explains. ‘By finding that baseline and actively reducing the cost of data generation, we can maintain high data quality without the exponential price tag.’
Another reason why experimental information is limited is because ‘the chemical industry heavily over-protects its data’, Abed says. The absence of unpublished experimental failures in scientific literature, and the presence of only limited ‘cherry-picked’ data, compound this issue, he adds. Abed therefore calls for open sharing standards for catalyst formulation and processing data, without potentially sensitive application information. ‘I point to the software industry as a blueprint, where open-source collaboration didn’t destroy value – it created it,’ Abed says. In the meantime, academic efforts are expanding their efforts to fill the experimental data gap.
How to overcome experimental and theoretical hurdles
Abed believes specialised centres will emerge to work on the experimental side of AI-powered catalyst discovery. He suggests that in the US the Department of Energy’s Genesis Mission and the National Science Foundation’s $1.5 billion (£1.12 billion) X-Labs programme might support them. In the UK, the University of Liverpool’s £100 million AI Materials Hub for Innovation project plan might serve a similar purpose.
Duarte notes that only a handful of academic groups have the necessary equipment for such work. ‘Getting the equipment accessible to use more broadly will be important.’ As a result experimental validations tend to be small in scope, she says. ‘Having 30 different variants of a catalyst or substrate is very impressive for an experimental group.’
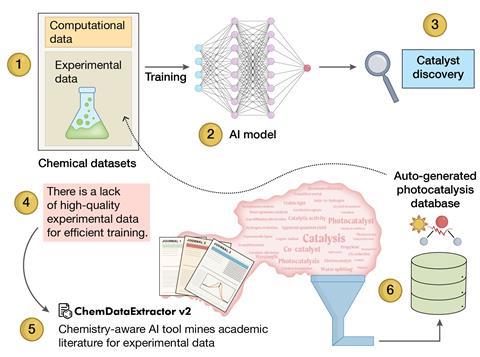
It might also be more economical to obtain experimental data from the existing chemical literature. To that end, Jacqueline Cole from the University of Cambridge in the UK and colleagues have developed an AI-powered tool called ChemDataExtractor v2. ‘It uses “chemistry-aware natural language processing” with language-model embeddings to mine the scientific literature for substance names and their properties,’ Cole explains.
Based on chemical names, ChemDataExtractor collates structure and property information from papers and other scientific documents, outputting them into structured databases. That involves tracking the name changes from reactants to intermediates to products, accurately matching each to their properties. The different material classes the researchers have built databases for using this method include 15,755 photocatalysts with water-splitting activity, extracted from 47,357 papers.
Another limitation for experimental validations of AI models is that they often look at organic homogeneous catalysts, as they are easier to make than inorganic heterogeneous ones. Organic molecules are also easier to represent using simplified molecular-input line-entry system (Smiles), which translates a chemical’s 3D structure to a string of symbols that machine learning systems can understand. Transition metal catalysts are often more difficult to represent, and surfaces even more so, Bernales adds. Modelling a surface or an organometallic ligand ‘needs a lot of manipulation from the computational chemists’, she says.
But now, El Agente can identify very complex transient transition states much faster, Bernales claims. ‘I went back to 10-year-old emails, where I had transition state structures that I wasn’t able to find at the time, involving several metal centres. This agent was able to find them in less than 20 minutes. It’s absolutely amazing.’ The few researchers in industry and academia who have tried it seem similarly enthused, she says.
Sargent is likewise impressed by the impact of six years of OpenCatalyst work, which his team has only felt in the last half-year. For example, in December 2025, a team including Abed and Sargent combined automated experimentation, human knowledge and machine learning to speed up discovery of a new carbon dioxide to propylene electrocatalyst. Using robots to synthesise and test 300 catalyst compositions over several days, they identified a copper–indium electrocatalyst that produced propylene with the highest Faradaic efficiency published to date.
‘There’s a lot of upfront effort that goes into the lab automation,’ Sargent stresses. ‘Developing the AI models, training off of computational data, existing experimental data, going after new data, and only then seeking record-breaking catalyst performance.’ And now scientists are looking to the ultimate way of judging such catalysts’ success – scaling them up into industrial applications.
The greatest challenge: scaleup
Today, catalyst scaleup is often a trial-and-error process, needing extensive formulation and fine tuning. Yet Sargent believes that AI and automation can help here too, especially if there are process variables that scientists don’t understand completely. ‘AI can help us discover hidden process variables, and thus to accelerate catalysis at scale,’ he says.
Sargent proposes using video cameras to record every material dispensed into a large-scale flask for scaled synthesis. ‘We put temperature sensors everywhere, monitor the whole system, acquire vast quantities of data,’ he says, and include electron and optical microscopy. He would like datasets including formulation and process chemistry, and manufacturing, enabling models to ‘learn the determinants of a well-dispersed, high-performing and stable catalyst’. ‘Developing systems that carry out those experiments autonomously should ultimately lead to more replicable formulation processes,’ Sargent says.
Having translated catalyst discoveries to larger scales at Dow Chemical, Bernales agrees that automation could improve this process. ‘We didn’t know compatibility with the solvents and other things that the chemical engineers knew,’ she says. Her current team has integrated machine vision into high-throughput metal–organic framework synthesis and characterisation, and created a tutorial for others to emulate them. ‘With AI, we expect that we’ll have a better collection and analysis of the data, and we’ll be able to avoid as much as we can this empirical factor.’
A major time-consuming frustration of Bernales’ industrial experience was trying to understand why her colleagues couldn’t replicate experimental or computed results. ‘At Dow Chemical, we did a lot of detective work trying to understand why something didn’t work,’ she says. ‘Once we understood, we were able to move forward, but that requires a lot of effort, a lot of money. With all the different AI tools being developed, I think there will be a big change, accelerating catalyst discovery.’
Andy Extance is a science writer based in Totnes, UK












No comments yet