Scientists make open-source database to test programs that learn chemistry
A team at Stanford University in the US has developed a benchmark for machine learning in chemistry. By providing a consistent way to test different techniques across a range of chemical data, it aims to accelerate the growth of this new type of scientific problem-solving.
Machine learning methods train a computer to efficiently get from raw data to already-known answers. Once the expected results are consistently reproduced, the software is ready to perform the same task with entirely new data. To fairly compare different learning approaches, research groups around the globe need to train and test their methods using a shared set of problems. Reference databases already exist for images and text; MoleculeNet, an extension of the DeepChem project, provides such a benchmark for chemistry.
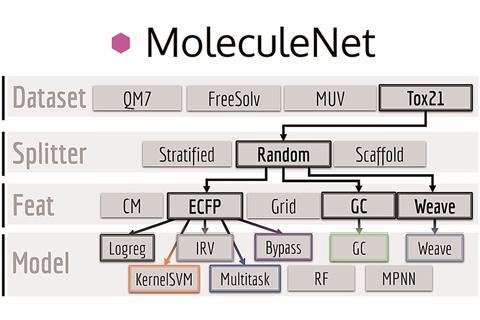
MoleculeNet’s reference data, curated from public databases, spans over 700,000 molecules and properties from electronic structure to physiology. Convenient software interfaces allow researchers to evaluate DeepChem’s library of machine learning techniques against this common reference point. In addition to the learning methods used, investigators can vary important parameters of the learning process such as the way molecules are described or how training data is chosen. These subtleties can have a significant influence on the results.
As an open source project, the designers intend for the benchmark to expand over time with an even greater variety of reference data and methods. Similar benchmarks in other fields provided an enormous boost to productivity; the researchers hope their benchmark will do the same for molecular machine learning.









No comments yet