
Scientists in Switzerland and the US have developed an ecosystem of tools to boost machine learning (ML)-based design of metal–organic frameworks (MOFs). Kevin Jablonka from the Swiss Federal Institute of Technology Lausanne (EPFL) and colleagues made Mofdscribe available to users in December 2022, some of whom have already published studies exploiting it. ‘This tool helps us to move forwards much faster,’ says Jablonka.
Today, chemists can make millions of distinct MOFs by connecting up metal nodes and organic linkers like molecular construction kits. Scientists have made over 100,000 MOFs with a potentially unlimited number possible, with uses including catalysing chemical reactions and storing gases including carbon dioxide.
The building blocks chemists choose can control the MOF’s properties, which makes their design critical. With a large chemical space to explore, researchers use computational design, with ML approaches predicting properties including gas adsorption, colours, oxidation states, heat-capacities, synthesis conditions and water stability.
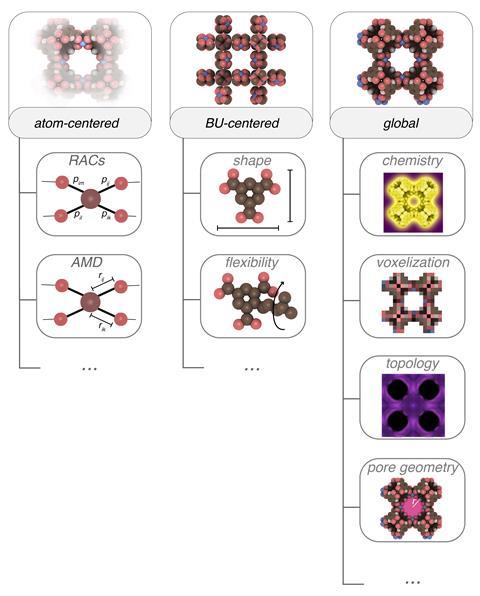
Working in Berend Smit’s EPFL team, Jablonka was frustrated by trying to work out if new ML approaches were better than old ones, finding it extremely difficult. ‘This is a very young field,’ Smit tells Chemistry World. ‘Many people are developing machine learning approaches and of course, they all claim that it’s an improvement.’ But Jablonka even had to reproduce systems developed in Smit’s group from scratch, because the code didn’t run.
Starting in March 2022, Jablonka started coding tools for the entire lifecycle of an ML MOF design process. ‘It gives you data, it gives you tools to then convert data into ML inputs, and then to test and compare models and also report and publish the results,’ he explains. Following 60,000 lines of code changes, the tools became the 20,000-line Mofdscribe ecosystem.
One key aspect of Mofdscribe is resolving problems with data used to train ML systems leaking into the test set. That’s a problem because it’s like letting the ML system cheat on its test by giving it the answers in advance. The problem arises because the same structure can appear in datasets multiple times, over 1000 in the worst case. As such it’s easy to miss the same structure going into the training and test sets.
Jablonka therefore developed tools to analyse datasets that ‘nobody even thought about needing’, according to Smit. Mofdscribe also allows its users to easily compare the performance of different ML techniques, Jablonka explains. It includes links to public leaderboards that benchmark the techniques.
Hilal Dağlar, a PhD researcher at Northwestern University in Evanston, US, already uses Mofdscribe after finding out about it on ChemRxiv and Twitter. She says that its main strength is making data preparation and cleaning for ML easier. Mofdscribe makes it easy to extract features from MOFs, she adds. ‘It offers an organised pipeline especially for non-specialist researchers in ML,’ Dağlar says. However, she would like to see it integrate new ML algorithms, including deep learning, and adds that Mofdscribe’s features must remain up to date to avoid its use decreasing.
References
K M Jablonka et al, ACS Cent. Sci., 2023, DOI: 10.1021/acscentsci.2c01177















No comments yet