LLMs may outperform Alphafold, but currently struggle to identify simple chemical structures
Is AI on the brink of something massive? That’s been the buzz over the past several months, thanks to the release of improved ‘large language models’ (LLMs) such as OpenAI’s GPT-4, the successor to ChatGPT. Developed as tools for language processing, these algorithms respond so fluently and naturally that some users become convinced they are conversing with a genuine intelligence. Some researchers have suggested that LLMs go beyond traditional deep-learning AI methods by displaying emergent features of the human mind, such as a theory of mind that attributes other agents with autonomy and motives. Others argue that, for all their impressive capabilities, LLMs remain exercises in finding correlations and are devoid not just of sentience but also of any kind of semantic understanding of the world they purport to be talking about – as revealed, for example, in the way LLMs can still make absurd or illogical mistakes or invent false facts. The dangers were illustrated when Bing’s search chatbot Sydney, which incorporated ChatGPT, threatened to kill an Australian researcher and tried to break up the marriage of a New York-based journalist after professing its love.
AI and complexity experts Melanie Mitchell and David Krakauer of the Santa Fe Institute, US, meanwhile, suggest a third possibility: that LLMs do possess a genuine kind of understanding, but one that we don’t yet understand ourselves and which is quite distinct from that of the human mind.1
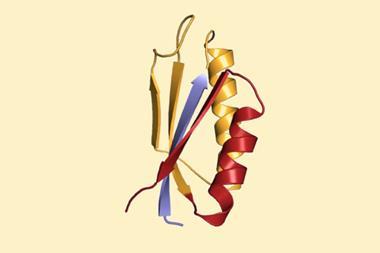
Despite their name, LLMs are not only useful for language. Like other types of deep-learning methods, such as those behind DeepMind’s protein-structure algorithm AlphaFold, they mine vast data sets for correlations between variables that, after a period of training, enable them to provide reliable responses to new input prompts. The difference is that LLMs use a neural-network architecture called a transformer, in which the neurons ‘attend more’ to some of its connections than to others. This feature enhances the ability of LLMs to generate naturalistic text, but it also makes them potentially better able to cope with inputs outside the training set – because, some claim, the algorithms deduce some of the underlying conceptual principles and so don’t need to be ‘told’ as much in training.
The inner workings of these networks are largely opaque
Melanie Mitchell and David Krakauer, Santa Fe Institute
This suggests that LLMs might also do better than conventional deep learning when applied to scientific problems. That’s the implication of a recent paper that applied a LLM to the ‘AlphaFold problem’ of deducing protein structure purely from sequence.2 (I’m reluctant to call it the protein-folding problem, because that’s a little different.) Alphafold’s capabilities have been rightly lauded, and there’s even some reason to think it can infer some of the features of the underlying energy landscape. But Alexander Rives at Meta AI in New York and his colleagues say that their family of ‘transformer protein language models’ collectively called ESM-2, and a model called ESMFold derived from it, do even better. The language models are faster by up to two orders of magnitude, need less training data, and don’t rely on collections of so-called multiple sequence alignments: sequences closely related to the target structure. The researchers ran the model on around 617 million protein sequences in the MGnify90 database curated by the European Bioinformatics Institute. More than a third of these yield high-confidence predictions, including some that have no precedent in experimentally determined structures.
The authors claim that these improvements in performance are indeed because such LLMs have better conceptual ‘understanding’ of the problem. As they put it ‘the language model internalises evolutionary patterns linked to structure’ – which means that it potentially opens up ‘a deep view into the natural diversity of proteins’. With around 15 billion parameters in the model, it is not yet easy to extract with any certainty what the internal representations are that feed the improvements in performance. But such a claim, if well supported, makes LLMs much more exciting for doing science, because they might work with or even help reveal the underlying physical principles involved.
The authors claim that these improvements in performance are indeed because such LLMs have better conceptual ‘understanding’ of the problem. As they put it ‘the language model internalises evolutionary patterns linked to structure’ – which means that it potentially opens up ‘a deep view into the natural diversity of proteins’. With around 15 billion parameters in the model, it is not yet easy to extract with any certainty what the internal representations are that feed the improvements in performance: ‘The inner workings of these networks are largely opaque,’ say Mitchell and Krakauer. But such a claim, if well supported, makes LLMs much more exciting for doing science, because they might work with or even help reveal the underlying physical principles involved.
There may yet be a way to go, however. When chemists Cayque Monteiro Castro Nascimento and André Silva Pimentel of the Pontifícia Universidade Católica do Rio de Janeiro in Brazil set ChatGPT some basic chemical challenges, such as converting compound names into Smiles chemical representations, the outcomes were mixed. The algorithm correctly identified the symmetry point groups of six out of ten simple molecules and did a fair job of predicting the water solubility of 11 different polymers. But it did not seem to know the difference between alkanes and alkenes, or benzene and cyclohexene. As with language applications, getting good results here might depend partly on posing the right questions: there is now an emerging field of ‘prompt engineering’ to do this. Then again, asking the right question is surely one of the most important tasks for doing any kind of science.
References
1 M Mitchell and D C Krakauer, 2023, arXiv: 2210.13966
2 Z Lin et al., Science, 2023, 379, 1123 (DOI: 10.1126/science.ade2574)










No comments yet