Kai Kohlhoff discusses the promise and pitfalls of doing science with distributed computing
Cloud computing is on the rise. Cloud services are already used quite routinely in collaborative research to share documents, papers and results. However, for the most part, computational research in chemistry or structural biology is still conducted on-site or in dedicated supercomputing centres, where data sets are not easily shared with the world. This is bound to change, and there has been a lot of discussion recently on preserving and sharing data.

Yet the cloud can be much more than a filing cabinet – it allows distributed teams to collaborate on shared data sets, enhances transparency and reproducibility and provides a worldwide platform to evaluate results. The cloud is ready for large-scale computational science. Are we?
Clouded thinking
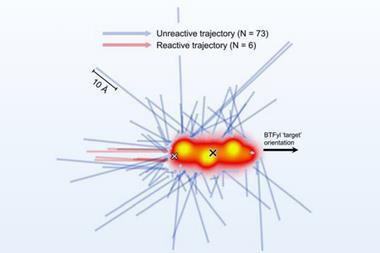
The cloud’s computational capacity is formidable, and it is already pushing the boundaries of challenging computational problems. My coworkers and I recently modelled 2ms of molecular dynamics for the adrenergic receptor protein ß2AR, surpassing the previous record on a dedicated supercomputer by an order of magnitude.1
But first, some words of caution. There is a steep learning curve, so be prepared to adapt and iterate. After weeks of writing scripts to run those simulations, I threw it all out – scaling it up on to tens of thousands of processers simply failed. My second attempt was good at generating enormous data sets, but the analysis pipeline wasn’t ready.
And don’t be seduced by sheer size – more data means little without clear questions and the right analysis. In the fitting and entertaining paper ‘Field guide to genomics research’,2 the authors use caricatures to represent pitfalls in high-throughput genomics. There is the farmer, who harvests data regardless of its usefulness, and the gold miner who searches for the elusive gold nugget in a dataset. The same warnings apply to working in the cloud: sound planning prevents wasted resources, and monitoring throughout stops early errors from amplifying.
Genomics illustrates another caveat of the cloud: favouring breadth over depth. Just before the turn of the century, decoding a gene sequence could take years, and earn you a PhD, affording time to reflect on the particularities of the gene. High-throughput sequencing shifted the focus from genes to genomes, revealing new relationships but blurring individual genes. Sophisticated algorithms that can detect faint signals in huge datasets can extract those subtle details. Developing them is time-consuming, but paramount for many large-scale computational studies.
Silver linings
Another advantage of cloud computing is eliminating the traditional concept of scarce, shared resources in individual labs, departments or high-performance computing centres. The cloud is a commodity with availability controlled by market forces.
I did my PhD in an office full of old, noisy workstations, where the noisiest machines were those of former students, now abandoned and forgotten. Having your own hardware has its benefits, but inevitably leads to inefficiency and burden, because the value of computing infrastructure deteriorates so quickly.
A sticker on engineers’ laptops at Google sums it up: ‘My other computer is a data centre’. Having a powerful workstation is great, but in a world where people are mobile and cloud resources are cheap and abundant, a laptop with an internet connection gives both flexibility and power.
Cloud infrastructure will only get cheaper and faster. Studies that use it can expect steady performance increases that require little to no effort from the user. Unchanged code will simply perform better over time. This also makes the cloud a good teaching tool, where setups can be shared between students, previous computations reproduced, and parameters varied for experimentation.
Ahead in the cloud
Up to now, many scientists have had to own and manage their computing infrastructure. No more. In the future, scientists will focus on science, while infrastructure specialists apply improvements behind the scenes. There will be streamlined processes for sharing data, not just when a study concludes, but even during retrieval and analysis.
By doing the analysis online and making the tools available to all, the transparency, resproducibility and, importantly, believability of computational studies are improved. This will increase confidence in scientific breakthroughs.
Cloud computing is no longer optional – it is a game-changer and it’s here to stay. So start exploring. Educate yourself, and start the discussion in your lab to see how you can take advantage of the new paradigm.
It will be worth it. The cloud enables new science, accelerates discovery and, like most disruptive technologies, it opens up unchartered territory. Today’s early adopters will shape the future of computational science and secure a clear competitive advantage. The next generation of scientists must be trained to use cloud resources whenever it makes sense. Then their work will be maintained and used indefinitely, and not end up abandoned in an office corner.
Kai Kohlhoff is a research scientist at Google










No comments yet