
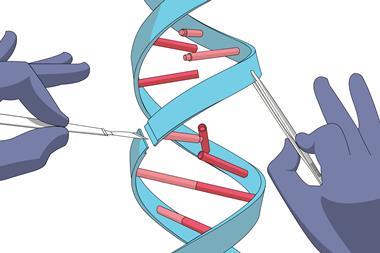
Crispr–Cas9 tool used to store information in the genome of living E. coli

In recent years, data as diverse as Shakespeare’s sonnets, Martin Luther King Jr’s ‘I have a dream’ speech and an Amazon gift card have all been stored as DNA. Now, scientists in the US have taken the idea one step further, inserting pictures and even simple movies into the genomes of living bacteria.
‘We’re piloting this system – what we call a “molecular recorder” – using images and movies, but we hope that it will eventually be used to capture information that we don’t already know, like what is going on inside of a cell,’ says Seth Shipman of Harvard University, who is part of George Church’s group which first demonstrated DNA could be used to store information in 2012.
He explains that DNA is a good storage medium as it is incredibly stable over time, ‘so for archiving data that you don’t plan to access very often, DNA can be a good choice’. But he adds that using living bacteria presents a new set of challenges. ‘Not only do you need to synthesise the coded DNA, but you also need to deliver it to cells and get them to incorporate the new bases into their genomes,’ he says.
To accomplish the task of turning DNA into a data storage medium the team turned to the Crispr–Cas9 system, which is part of the bacterial immune system which enables them to take up and store genetic material from invading viruses in a specific region of the genome. In the first of their proof-of-concept experiments, the pixels that made up a black and white photograph of a human hand were encoded into the genome of Escherichia coli.
The group tried different strategies to encode the data. ‘One was rigid, four colours with a base corresponding to each colour. That code didn’t work so well because it ended up creating some sequences that were not very compatible with the biology of the system,’ Shipman says. ‘We ended up using a more flexible code, similar to the codon code used to make proteins. In this code, we had 21 colours and each could be coded by three different nucleotide codes. That way we could flexibly create the DNA, avoiding problematic sequences.’
Horse play
The team also encoded five frames of a galloping horse from Eadweard Muybridge’s Human and animal locomotion photography collection into E. coli. The frames were inserted one by one over time, so that they would be encoded in the right order and could be recovered to create a movie.
The information could later be recovered fairly simply, as all the new sequences are stored in a single region of the E. coli genome. ‘So we just amplify that one spot from many cells and look for sequences that were not there before,’ says Shipman. The pixel data could be read with about 90% accuracy.
‘Our next step is to hook this system up to biology so that it might record a process that we don’t yet understand, rather than information that we already know,’ says Shipman.
Ewan Birney from the European Molecular Biology Laboratory’s European Bioinformatics Institute, near Cambridge, UK, says the idea of a ‘little black box’ for recording information in cells is interesting but ‘a bit fanciful’. ‘The exciting thing really is that they’ve got a high information content writing system, not really that they store information in DNA,’ he says. ‘The thing I was most impressed about was the ability to do that amount of designed Crispr simultaneously.’
‘The applications they used that for doesn’t actually change the dial in terms of making practical DNA storage.’
References
S L Shipman et al, Nature, 2017, DOI: 10.1038/nature23017










No comments yet