The more we learn about DNA, the less we seem to know, as Philip Ball discovers
Sixty years ago, James Watson and Francis Crick unlocked the chemical basis of genetics.1 By deducing the structure of DNA from the x-ray diffraction work of Rosalind Franklin and Maurice Wilkins, they revealed that genes are encoded in a four-letter chemical alphabet along the strands of the double helix. These genetic messages are translated into the proteins that orchestrate an organism’s biochemistry. Random errors in copying DNA during germ-cell formation provide the raw material from which, once translated into the organism’s protein phenotype, natural selection gives rise to evolution. DNA is the molecular root of genetics.
At least, that’s the usual story, and it’s one you are likely to hear many times during this diamond anniversary year. Well, don’t you believe it.

It is not exactly untrue – but it is misleading in ways that are becoming increasingly important for the potential promise of the genomic age. For here is the blunt truth: many specialists on the matter of how DNA works are starting to question even whether this molecule is the carrier of genes. Some are either reverting to the old notion of genes as abstract, conceptual, heritable entities whose material embodiment is neither known nor perhaps terribly important. Others have almost ceased to talk about genes at all.
Such revisionism should not be taken too far. There is no serious doubt that DNA plays a central role in the inheritance of traits and the development of an organism. It is still valid to speak of DNA encoding the structures of proteins, and DNA is still evidently the fabric in which essential information is recorded about how the molecular machinery of an organism operates. This, however, is not the same as saying, as some geneticists continue to, that the sequence of base pairs in DNA is the blueprint of the organism or the ‘book of life’. The latest dispatches from the forefront of molecular genetics suggest it is not as simple as that.
Once upon a time
It has often been remarked that Watson and Crick’s seminal discovery in 1953 mirrored almost eerily the notion of digital information emerging from computer science at that time. Just as magnetic tape was being used to encode information in a series of binary ones and zeroes, so this double-stranded molecular tape used a quaternary system of adenine, thymine, guanine and cytosine bases to record information about building proteins in a linear fashion.
Over the ensuing decade or so, Crick and others deduced how the genetic code works. Thanks in particular to the work of the American biochemists Marshall Nirenberg, Har Gobind Khorana and Robert Holley, who shared the 1968 Nobel prize in medicine for their work, it became clear that each amino acid in a protein is encoded in a triplet of DNA base pairs (a codon), and that a protein-coding sequence is ‘transcribed’ into messenger RNA, which then acts as a template for putting the amino-acid chain together. The idea of a one-way flow of information from genes to proteins, first suggested by Crick in 1958, became enshrined as the ‘central dogma’ of molecular biology: as Nirenberg put it, ‘DNA makes RNA makes protein’.
Then there was the problem of junk DNA. As it became possible to decode DNA sequences in the 1960s and 70s, researchers discovered that most of the genome – the complete complement of DNA – does not code for proteins at all, and seemed to have no clear function. This stuff was thought to be the useless accumulated residue of evolution: defunct files that were not cleared out, such as extinct genes and miscopied fragments that, lacking any serious detrimental effects, were never tidied up by selection. What’s more, DNA genes themselves were not as simple as first thought: they contain sequences that are edited out of the RNA transcript before being translated into protein. Sometimes the transcript gets reshuffled in the process, so that a single gene might encode several different proteins.

The Human Genome Project, which unveiled the first draft of the complete human genome in 2000, complicated rather than resolved this picture.2 While much was made of this sequence revealing ‘what it means to be human’, in fact the function (if any) of most of it remained mysterious. And the number of human genes turned out to be rather alarmingly small – just 25,000 or so, which seemed barely sufficient for such a complex (so we like to think) organism.
All this led some researchers to question the gene-centred view of molecular biology. ‘We have fitted ourselves out with a magnificent set of blinkers’, wrote Oxford physiologist Denis Noble in his 2006 book The music of life: Biology beyond genes. ‘We have rendered ourselves incapable of looking at the relationships between the genetic code and living systems in any other way.’
Decoding Encode
Noble challenges the standard view of causality from gene to organism. He points out, for example, that genes on DNA can only function in an environment already imbued with a lot of ‘implicit’ information. For example, genes might specify the proteins needed to make lipids, but there is nothing in genes per se that directs lipids to self-assemble into the complex compartments in cells. What’s more, the way some physiological processes, such as calcium-ion signalling in muscle activity, operate depends on mechanisms that rely on higher-level interactions than genetic ones: you will never understand them by searching in the genome. A gene-centred approach that looks for phenotypic correlation with changes in genotype generally does not work, Noble says, because such changes in genes are ‘buffered’ by the networks of gene interactions – which makes it impossible to test notions of ‘selfish genes’ because one cannot even define what such selfishness actually means.3
Such views have trouble penetrating the carapace that genetic research has created. Ironically, however, it is that very research that is now providing some of the most serious challenges to DNA’s supposed hegemony. One of the most significant of these was uncovered last year, when the key findings of a project called Encode were announced.4 Encode aims to tackle the difficult question that was swept under the rug during the triumphant celebrations of the Human Genome Project: what do all these DNA sequences actually do? The prevailing view was that only about 5% of the genome was ‘active’ and biologically relevant, either by encoding proteins or regulating other genes. The rest was, if not necessarily ‘junk’, then at least of little consequence.
Encode trod roughshod over this vision. It found that as much as 80% of our genome is transcribed – that is, copied by enzymes into strands of RNA.5 Transcription was, in the picture of genetics that flowed from Crick and Watson’s discovery, primarily about making RNA templates on which the peptide chains of proteins were assembled. More recently, it became apparent that some RNA transcripts do not get expressed as proteins, but have their own role as regulatory elements of the genomic network, the interactions between ‘DNA genes’. But Encode showed that the real situation is much more extreme than that: transcription and RNA are where the real action is.
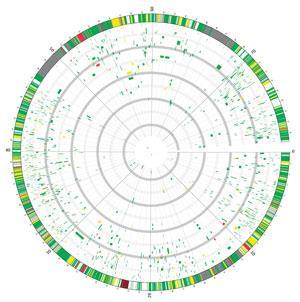
What’s more, this high degree of transcription means that many, perhaps most, of the ‘genes’ on DNA overlap with other sequences that are also transcribed: DNA is not simply a string of ‘genes’ interspersed with non-functional material. That prompts the question of what such supposed ‘genes’ in DNA really are. It also throws into question how DNA is shaped by evolution, given that only about 5% of the genome seems to be subject to selective pressure while much more has a functional role. It had long been assumed that non-protein-coding sequences that are transcribed but are not ‘conserved’ between different species cannot have any functional role because apparently evolution does not consider them worth preserving. But there is now reason to think this is wrong, and that these non-coding RNAs might undergo rapid evolution subject to different constraints from coding sequences.6
The findings of Thomas Gingeras and colleagues in Encode have forced them to a dramatic and controversial conclusion: that genes are not on DNA at all. ‘We would propose that the transcript be considered as the basic atomic unit of inheritance,’ they wrote. ‘Concomitantly, the term gene would then denote a higher-order concept intended to capture all those transcripts … that contribute to a given phenotypic trait.’5 In other words, a ‘gene’ would no longer be seen as a material entity, a string of bases in DNA, but would be a more abstract and loosely specified concept. This would not change anything much in the standard approaches to population genetics – which do not rely on any specific notion of a gene’s material basis, and indeed were largely developed before Watson and Crick – but it places the current era of genomics in a very new light.
This new view places much more emphasis on what the RNA transcripts do. It is a view shared by molecular biologist John Mattick of the Garvan Institute in Sydney, Australia. Most of the information held in the human genome, he argues, ‘is involved in complex regulatory processes that underpin development and brain function. This includes the vast numbers of non-coding RNAs and DNA transposons [sequences that can ‘jump’ around the genome], which rather than being junk, appear to provide the regulatory power and plasticity required to program our ontogeny and cognition.’7 In Mattick’s view, this makes RNA ‘the computational engine of the system’ – the DNA is just the hard drive, but the RNA supplies the real software.
Overwriting the book
That is not the only reason to re-evaluate the role of DNA in genetics. Ironically perhaps, it is the immense increase in genomic data made possible by techniques developed for sequencing that has highlighted some potential problems with the conventional picture. One of the biggest puzzles concerns traits and diseases that have a complex genetic component. While some inheritable diseases and human variations can be linked to mutations of a single protein, most of them – such as intelligence or height, say – seem to be influenced by many different regions of the genome, often ones that are involved in gene regulation rather than protein coding. But what is perplexing is that, while it is possible to quantify the genetic influence on such traits, the genomic regions so far linked to them seem able to account for only a very small proportion of that influence. The ‘missing genetic material’ is sometimes called the dark matter of the genome.
There are various possible explanations for this, but one of them is that the dark matter is not encoded in the DNA sequence at all. For example, the information in the genome can be modified by the addition of chemical ‘markers’ such as methyl groups to DNA bases or the histone proteins on which the strands are wound in chromosomes, which may switch genes on or off. These so-called epigenetic modifications can be conditioned by the organism’s environment, and are usually wiped clean when DNA is replicated to make new gametes. But that does not always happen – some epigenetic markers may be inherited.
Last year a team led by Joseph Nadeau of Case Western Reserve University School of Medicine in Cleveland, Ohio, reported an epigenetic modification in male mice affecting susceptibility to cancer that could persist for at least three generations.8 According to Mattick, this and similar findings show that ‘epigenetic inheritance may be far more important than expected’, which ‘challenges the fundamental tenets of genetics’.9 Nadeau has shown that this epigenetic inheritance is mediated by non-coding RNA. What’s more, such RNA-directed modifications seem able to feed back from somatic (body) cells into germ-line cells – something held by traditional genetics to be forbidden, because of its Lamarckian undertones.
In Mattick’s view, these findings add to the argument that RNA, not DNA, might be at the heart of genetics. ‘If RNA editing can alter hardwired genetic information in a context-dependent manner, and thereby alter epigenetic memory, it is feasible that environmental history may shape phenotype, and provide a far more plastic and dynamic inheritance platform than envisaged by the genetic orthodoxy of the past century’, he writes. ‘RNA may be the computational engine of the evolution and ontogeny of developmentally complex and cognitively advanced organisms.’9
A new role
If that is the case, then what exactly does DNA do? Whole-genome sequencing projects such as that for the human genome do not really face this question. They survey the DNA landscape – for example, the statistics of base-pair distributions (such as C-G-rich regions), the extent of gene duplications and the differences and similarities between species – without bothering too much about what all this molecular material is for.
DNA is an information store which can be copied pretty accurately
Steven Rose
But we can start making a few suggestions. Evidently DNA is central to inheritance. Evidently it does encode proteins, evolve in response to natural selection, and contain information about how organisms develop. The question is perhaps how best to think about that information. In the view of some biologists, such as Noble, the DNA sequence represents just one among many ‘layers’ of information that contribute to an organism. ‘The genome is only one of the databases,’ he argues. ‘Function in biological systems depends on important properties of matter that are not specified by genes.’
Perhaps DNA might best be seen not so much as a blueprint but as a sketch, a shorthand aide-memoire, a little like the musical scores written down by Mozart or Beethoven in which not all the notes or dynamics are indicated because much of the information can already be taken for granted, residing instead in the musicians who will play the score. It is just the operating system supporting the RNA software. ‘I see DNA as a formatted database, used by the organism to do many things, just as a child makes many different things with the same set of Lego pieces,’ says Noble. Biochemist Steven Rose of the Open University has a similar perspective: ‘DNA is an information store which can be drawn on by cellular processes during development and can be copied pretty accurately and transmitted during cell division and reproduction. But in itself it conveys no meaning; meaning is provided by the cellular context in which DNA is drawn upon. What DNA certainly is not is any of those metaphors of master molecule, book of life and so on.’
In this view, DNA is not an exhaustive blueprint because it does not have to be. The ‘language’ it encodes is like a real language: imprecise, incomplete, acquiring meaning only when it is spoken in the right context and environment. It is time to stop worshipping at the altar of the double helix and to see DNA for what it really is.
Philip Ball is a science writer based in London, UK
References
1 J D Watson and F H C Crick, Nature, 1953, 171, 737 (DOI: 10.1038/171737a0)
2 E S Lander et al, Nature, 2001, 409, 860 (DOI: 10.1038/35057062)
3 D Noble, J. Physiol., 2012, 589, 1007 (DOI: 10.1113/jphysiol.2010.201384)
4 M Skipper, R Dhand and P Campbell, Nature, 2012, 489, 45 (DOI: 10.1038/489045a)
5 S Djebali et al, Nature, 2012, 489, 101 (DOI: 10.1038/nature11233)
6 K C Pang, M C Frith and J S Mattick, Trends Genet., 2006, 22, 1 (DOI: 10.1016/j.tig.2005.10.003)
7 J S Mattick, FEBS Lett., 2011, 585, 1600 (DOI: 10.1016/j.febslet.2011.05.001)
8 V R Nelson et al, Proc. Natl Acad. Sci. USA, 2012, 109, E2766 (DOI: 10.1073/pnas.1207169109)
9 J S Mattick, Proc. Natl Acad. Sci. USA, 2012, 109, 16400 (DOI: 10.1073/pnas.1214129109)











No comments yet