
A new tool hopes to make public metabolomics data more accessible through structure-based searching. Named StructureMASST , the platform returns every spectrum in its database where a molecule, structure or substructure has been seen before.
Public metabolomics data is growing ever more abundant, with increasing diversity. Methods of searching raw mass spectra have adapted to meet this rise: the introduction of indexing technologies to the Mass spectrometry search tool (MASST) in 2020 condensed a 20–40 minute search of metabolomics data to just seconds across over a billion mass spectra. Yet current methods still struggle with structure- and substructure-based searches where names of molecules or Smiles are used. A single molecule can have multiple different names, for example, making it an arduous task to find all its relating mass spectra.
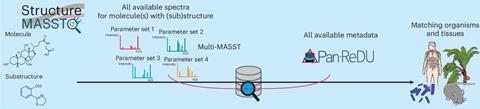
A team led by scientists at the University of California, San Diego and the University of California, Riverside, developed StructureMASST in answer to this issue and a second, more important problem. Cross-repository searches can be complicated by datasets that come from a range of instruments and acquisition conditions. Using StructureMASST, scientists can search across several major public metabolomics repositories, scanning multiple MS/MS spectra at once to find the organisms, organs or health conditions associated with a molecule.
The platform builds on pre-existing and well-developed metabolomics data repositories, informatics tools and workflows, including MASST and Pan-ReDU – a community resource that standardises metadata across metabolomics datasets to enable large‑scale comparative analyses. StructureMASST expands on Pan-ReDU’s success, by including data from the NORMAN/DSFP suspect screening repository and meta-visualising results with Sankey plots. The ability to filter over 1.5 million spectra by chemical name or structure and then search across all corresponding MS/MS for those molecules adds to its merit.
The result is a comprehensive dataset for users, with a simple method of obtaining them. The team believes StructureMASST will empower hypothesis generation, improve discovery and reveal new insights into metabolism, exposure and microbial interactions.
References
Yasin El Abiead et al, Nat. Biotechnol., 2026, DOI: 10.1038/s41587-026-03082-8















No comments yet