
A unique collaboration between chemists and linguists links linguistic considerations with information storage for the first time. The interdisciplinary project has resulted in the successful encryption and subsequent decryption of a Confucius proverb in both Unicode and Zhèng Mă using sequence-defined polymers.1
DNA, the most famous naturally occurring information storage polymer, stores vast amounts of genetic information in a comparatively small volume using four nucleotide bases. Inspired by the storage capacity of DNA, chemists have begun to examine other sequence-defined polymers for storing data.
Last year, a team led by Eric Anslyn from the University of Texas at Austin encoded a passage from Jane Austen’s Mansfield Park in hexadecimal using sequence-defined oligourethanes.2 These oligourethanes were then iteratively degraded using 5-exo-trig cyclisation and read using liquid chromatography–mass spectrometry (LC–MS) to retrieve the hexadecimal code, which was then translated back into the original passage.3

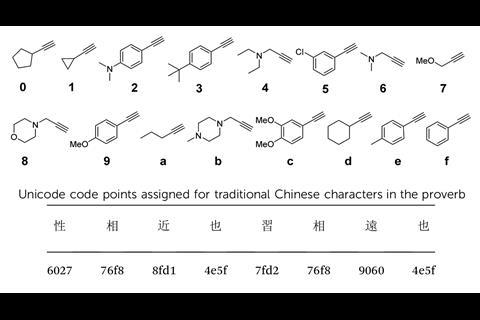
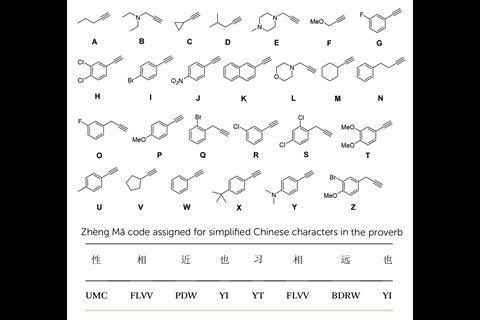
Now, the team has turned its attention from alphanumeric languages to logographic script. ‘[We] decided to explore other language forms and chose Mandarin as a paradigmatic example of logographic symbology. But to do so, we felt a collaboration with linguistic experts would create a thorough and sophisticated analysis,’ says Anslyn. To evaluate a suitable method to accurately encode a well-known Confucian proverb, Anslyn’s group teamed up with Danny Law’s team from the University of Texas at Austin’s department of linguistics. Together they translated the proverb into both Unicode (base-16) and Zhèng Mă (base-26); the latter being well suited to encoding the complexity of symbolic Chinese language, producing codes up to 4 letters long.
While the Mansfield Park study relied on synthesising and purifying individual monomers, the new project removed this aspect by using solid-phase synthesis to create a repeating oligourethane backbone containing azide groups. Using copper-catalysed azide-alkyne click chemistry, the team added commercially available alkynes on to the oligourethane backbone. Each alkyne molecule represents a letter, encoding the information here rather than in the oligourethane backbone.
‘What I really like is that this is a collaboration between linguists and chemists, and they’ve really put their minds together,’ remarks Christopher Barner-Kowollik, a polymer chemist from Queensland University of Technology in Australia. ‘How does the coding need to look so that, in this example, we can code the content of Chinese or Japanese characters. I find that utterly fascinating.’
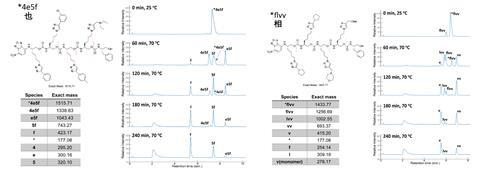
Anslyn’s team’s method for chemically encoding information can potentially work for any language. Expanding the library of monomers would accommodate different codes with increasing numbers of bases. ‘The biggest advance is to bring other disciplines into the arena of sequence-defined polymers,’ Anslyn asserts. ‘We feel that the tie to linguistics creates new affordances for sequence-defined polymers, that we are pursuing and that we hope inspires others to pursue.’
References
1 L Zhang et al, Chem. Sci., 2024, 15, 5284 (DOI: 10.1039/d3sc06189b)
2 S D Dahlhauser et al, Cell Rep. Phys. Sci., 2021, 2, 100393 (DOI: 10.1016/j.xcrp.2021.100393)
3 S D Dahlhauser et al, J. Am. Chem. Soc., 2020, 142, 2744 (DOI: 10.1021/jacs.9b12818)













No comments yet